|
|
Post by us4-he2-gal2 on Jul 30, 2007 1:33:04 GMT -5
Overview: A move to typographical correctness: Although its not explicitly stated in any current guideline or rule, I assume all present suspect and know the orientation of this board as a whole. While it may not be spelled out, Enenuru content is hoped in practice to display an adherence to scholarly finding, a respect for it, and a commitment to benefit from it in very rare ways. The orientation of the board is thus, in my definition, toward the academic side of things although most of us are not scholars, it is a tribute to ANE learning, in itself and as the cure to mankind's collective amnesia (so to speak). The point of this thread, "from fingers to forks", is to further sophisticate this project, to discuss scholarly convention and to dare exploration of the topic of ANE linguistics. My aim here, and I hope as many people will share it as is possible, is to start an open exchange of information and factoids which will bring the board to a necessary level of what I'll term "technical correctness" and to help avoid the spread of any inaccuracy. In case anyone might mistake an air of condescension in any of this, I should explain this is a personal change I would like to make, in line with my overall ambition for Enenuru. But I post it here in the event others would also like to learn or to contribute, and to sophisticate their own contributions to this board and elsewhere. I also hope it may function like a quick reference for posters. (I should also explain the idea here stops well short of an ambition to learn Sumerian, at present, it is "merely" to better handle the secondary material. All efforts will be made to be concise.)
- - Homophony and its Transliteration conventions - - (Yes I named myself us4-he2-gal2 without knowing what the numbers meant.) [ From Introduction to Akkadian, R. Caplice, On Homophony] "d. Alphabetic representation of Akkadian texts. We have seen that the phonetic values of a sign can be represented in alphabetic script: thus AN has the values /an/ and /il/. It is characteristic of the cuneiform writing system (due in part to the nature of the Sumerian language) that a given syllable may be represented by any one of several homophonous signs; in order that alphabetic representations might indicate which sign is actually in question, modern scholars distinguish syllables by index numbers, following a standard listing compiled by the French scholar Francois Thureau-Dangin [...]. Thus the syllable /tu/ may be indicated by the signs 'tu one', [another one], 'tu two', [another one], 'tu three'. ,'tu four', etc. In alphabetic representation, the first of these is unmarked, the 'two' and 'three' values are indicated by acute and grave accents, and further values by a subscribed number: tu, tú, tù, tu4, tu5, etc. (A notation tu[x] indicates a value /tu/ assigned to a sign but not yet listed in modern sign-lists.) Such accents have no phonetic significance."
Homophonous, being a word neglected in most walks of life, means (as my dictionary informs me) simply "having the same sound." So despite the accent marks the above examples of tu all have the same sound, yet a different meaning. As an explanation at etcsl goes etcsl.orinst.ox.ac.uk/edition2/cuneiformwriting.php: Etcsl on Homophony: "Another challenge for the aspiring Sumerologist is the fact that different signs are used to code the same phonetic value, that is homophony. To distinguish between homophonous signs subscript numbers have been introduced. gu ( = GU), gu 2 ( = GU 2), and gu 3 ( = KA) are good examples. An English parallel would be the word 'bust'. If you look this word up in a dictionary you will see that there are two entries, (often) distinguished by superscript numbers, although the words are pronounced the same. This is because they have different, unrelated meanings, just like gu = 'cord/net', gu 2 = 'neck/bank', and gu 3 = 'voice'. In the example with gu/2/3 the same phonetic value stems from different signs AND have different meanings" But they say "this is not always the case." Perhaps we can comprehend "heterography" later.. For now just think "Im on top of a spining top" or "I smell rank because I am first rank." or "I have a whole gross of gross" but again to use the etcsl example "There was a great bust yet my ogling-through-my-big-black-framed-glasses was a bust." Anyway Im glad to begin to unravel what to me has been a minor mystery, that is a clear definition of why a transliterated word will appear with this or that subscript number. One other relevant piece I have is from the etcsl "transliteration conventions" (http://etcsl.orinst.ox.ac.uk/edition2/encodingdisplay.php) Accents for Homophony: "Diacritics which are sometimes transcribed as acute and grave accents over the vowel (á, é, í, ú and à, è, ì, ù) to show a value of a sign are here marked with subscript 2 and 3 respectively. So you will find zu 2 not zú and dug 3 not dùg." So at the acute or grave accents are of the same function as subscript 2 or 3, these also being modern conventions indicating difference in meaning of syllables that sound the same. Summary of Accents: 1. The accents which govern the interpretation of homophonous signs are á, é, í, ú and à, è, ì, ù (they are note phonetic accents.) See attachment below for further illustration of Homophony. 2. There are four additional accents commonly seen in Sumerian transliteration which when applied make 'special consonents.' These are phonetic accents and effect pronounciation. They are š, ḫ, g̃, ĝ -The letter š is called "shin" the accent itself a "caron". Pronounced and š is pronounced like sh in dash." - ḫ simply enough is "h with breve below" the accent is a "breve". pronounced like ch in German Buch or Scottish loch - g̃ is "g with tilde". ĝ or "g with circumflex". Some German Sumerologists use the circumflex as oppose to tilde. Both are pronounced like ng in rang. copy á, é, í, ú and à, è, ì, ù also š, ḫ, g̃, ĝ Š, Ĝ, paste For ease of reference, here are some Akkadian accents ē, ṣ, ī, ā, ū, û, ṭ , â most recently there is ê (to be delt with elsewhere) (For the above information on phonetic accents I referred to J. Holloran's Sumerian lexicon, and the pdf transliteration principals by J. Black.) Addition 12/06 A few basic transliteration principles are explained in the front of Michalowski's "Letters from Early Mesopotamia": [ ] Single Brackets enclose restorations. (While Half brackets enclose partially destroyed signs) : A colon in the transliterations designates signs in reverse order < > Acute brackets enclose words omitted by the original scribe. ( ) Parantheses enclose additions in the English translation. ... A row of dots indicates gaps in the text or untranslatable words. PN = personal name. Italics in the English translations indicate uncertain renderings. Cheers.
|
|
|
|
Post by us4-he2-gal2 on Jul 30, 2007 23:05:50 GMT -5
- - Polyphony: An all important feature - - (The information in this post may have no direct application for Enenuru posting, but is something I believe may improve comprehension of secondary literature) From The Sumerians ( S.N.Kramer 1963) H.C. Rawlinson is credited as being the first to recognize polyphony within Cuneiform script, an insight which would be key to decipherment of script as a whole. Kramer relays: "In the year 1847, Rawlinson traveled once again from Baghdad to Behiston and at the risk of life and limb succeeded in making paper squeezes of the Babylonian version, which gave him a long text of 112 lines that could be deciphered and translated with the help of already deciphered Old Persian text on the same monument. In the course of this work, moreover, he discovered the other all-important feature of Babylonian writing, "polyphony," that is, that one and the same sign could stand for more than one sound or "value." ' A principal characteristic' - From Richard Caplice's Introduction to Akkadian c. A principal characteristic of the writing system so developed is that each sign may be polyvalent : it may represent different values, just as a single letter-symbol may represent a variety of phonetic realizations in written English. The reader of Akkadian must rely on contextual indications to tell him whether he should read AN as a logogram 'sky' or 'god' or with the phonetic value /an/ or /il/. Normally these indications suffice; very rarely, they allow more than one reading, and so leave the text ambiguous. -Something of what polyphony means in practice: www.sron.nl/~jheise/akkadian/title.html (John Heise) In translating cuneiform there are a number of important steps the first somewhat obvious, the second directly relevant here: Step 1. Recognize the sign Step 2. Determine the sign value How does the professional know how many values a given sign might have or have many values it might be limited to? How do they know if given sign might (mercifully) have just one value? If total recall of a sign isnt available, and maybe even still, the way to determine a sign value for the cuneiformist would appear to be by "using a choice of values also given in signlists. In syllabic writing each sign stands for a syllable (has phonetic value), but the same sign may have different phonetic values (polyphony). The correct choice should make a meaningful word. The same sign may also stand for an entire word (has logographic value), usually more than one word. The choice depends on the context." This is transliteration. Signlists: What a good idea - www.sron.nl/~jheise/akkadian/Welcome_list.html (John Heise) Ive been informed of three sign lists which I believe are still current or in use they are 1. Rylke Borger, 'Assyrische-babylonische Zeichenliste' (in German) 2. R.Labat and F.Malbran-Labat, 'Manuel d'epigraphie akkadienne, signes, syllabaire, ideogramma', (in French) 3. Wolfram von Soden, Wolfgang Röllig, 'Das akkadische Syllabar', 1991 (In German) I have the German of a five year old now, so its scary all the dots Id be connecting with one of those babies. Or not. In the meantime Ive got a hint of what it might be like to read one of these, translated into english as it is (see the above link.) Under Table of Contents, click "29 signs, list 2", and then see Borger sign 15. In the above Heise states that a sign may have multiple phonetic values, and at the same time it may also have multiple logographic values. In this signlist entry, sign 15 is given as having 5 logographic meanings [Sumerian] 1. KA `mouth', 2. DUG4, DU11 `to speak' 3. GÙ `to shout', `to proclaim' 4. inim `word', `message', `order', `decision' 5. ZÚ `tooth' [followed by a sixth instance of a compound verb] Polyphonic signs then, may sometimes have meanings with semantic relationship, potentially making selection of the exact appropriate meaning more difficult, although Heise remarks "The choice of phonetic values for a sequence of cuneiform symbols is made such that a sensible word comes out. Surprisingly, the choice is in most cases unique and rarely one is left with some ambiguity. Polyphony makes the reading of cuneiform difficult for the layman." Difficult Surely he's joking.. I should mention there is some cdli activity on sign lists: early-cuneiform.humnet.ucla.edu:16080/wiki/index.php/Sign_listsFollowing the urls Ive added an illustration of the above mention polyphonic sign (KA):: Helpful urls: www.sumerian.org/sumerian.htmwww.sron.nl/~jheise/akkadian/Welcome_cuneiform.htmletcsl.orinst.ox.ac.uk/edition2/cuneiformwriting.phpwww.ancientscripts.com/sumerian.html |
|
|
|
Post by us4-he2-gal2 on Aug 21, 2007 4:24:04 GMT -5
The below post will go deeper into foreboding subject of Sumerian grammar and language. The act seems to be a little like shining a pen-light into the Grand Canyon at midnight, and I'm sure my personal limitations are demonstrated to any philologically inclined persons here. Still I feel the thread goal of 'increased accuracy in the handling of Secondary sources' is served by these explorations (which fall short of trying to learn Sumerian.) I've been glad to utilize, rather closely, a number of concise and accessible Etcsl articles, urls listed at the bottom.
Hyphenation Principals, Morphemes, Clitics and so on Word Boundaries: Geting back to transliteration conventions, and the effort to handle secondary materials effectively, there are the Hyphenation Principals for transliterations. Omnipresent, familiar, yet for an "interested non-specialist" like myself, its tempting to say 'not so simple.' In a brief article [note 1] "The transliteration of Sumerian" Jeremy Black (2004) explains: "When represented in roman script, the syllable signs that make up a Sumerian word are written joined together with hyphens" As a visualization of this, the first line of the first transliteration at Etcsl (t.1.1.1) reads: "1. iriki kug-kug-ga-am 3 e-ne ba-am 3-me-en-ze 2-en kur dilmun ki kug-ga-am 3" Seems simple so far. One would imagine then that kug, kug, ga and am 3 each have a sign on the tablet, and given the hyphens, have been interpreted as composing a single Sumerian word in this case. Yet cuneiform texts lack explicit syllable grouping on the cuneiform tablet, and in many cases are written with no spaces to separate words. How is the modern specialist able to determine 'word boundaries' then (where a word begins and ends within a sequence of syllables?) In "Hyphenation Principals" [ 2] Black mentions: "Sometimes the judgment whether something is a lexicalised compound or an ad hoc phrase is based on frequency of occurrence. Sometimes the judgment is informally based on (Akkadian, European language) translation value. Ideally the judgment would be based on syntactic grounds, e.g. can the compound itself be modified by an adjective? At all events, it must be pragmatic, since language is irregular, but decisions are needed. Sometimes this will help with lemmatisation, by disambiguating homographs. Sometimes the decision is taken on grounds of convenience. Multiword verbs exist in which the lemma is composed of two words (which, in a finite verbal form, are separated by proclitics). "Morphemes and Clitics: psd.museum.upenn.edu/ppcs/morph-exp.htmlThe above glance in itself conveys some of the texture of the task, though more illustrative for those surveying with me here, might be two problems in deciding word boundaries that Black has pointed to.
Problem 1: "Clitics are frequent in Sumerian, and it is not always clear if something is a word in its own right or only a clitic. "First it should be said that a morpheme is a term that designates "the smallest grammatical units in a language", and with Sumerian a morpheme might modify a word in numerous ways. At the above PSD link, there is a list of Morpheme Correspondences, which will help illustrate what a morpheme might do. One example is pluralization, "the plural of certain nouns in Sumerian is indicated by a morpheme, called a plural marker" [ 3] in the case of the noun, the correspondence gives the plural marker as "ene". I believe an English equivalent of a plural marker morpheme would be the s that modifies the word 'boy' to 'boys.' Clitics are also a class of morpheme, and unlike the plural marker (which appears differently in form when attached to a noun or verb), Clitics appear the same regardless of the world class they are attached to. Many Sumerian words consist of a root form ("possibly reduplicated") and a chain of more or less clearly distinguishable and separable affixes or clitics. [ 4] "They may often have been phonologically integrated with their hosts; the writing system certainly writes most of such clitics as if they were in sandhi with the previous word (or clitic)" [ 2] An example of a type of clitic is the genitive clitic - ak 'of', which denotes ownership. Here is - ak in action: "e 2 lugal- ak-a house king-GEN-LOC (translates to) "The house of the king " [ 5] In any case, its not easy to grasp the linguistic lingo, and accompanying implications. After something of these have been grasped at, its not as difficult to take in the significance of Problem 1 however.
Problem 2. 'In Sumerian a large number of compound nouns exist ' This issue here is somewhat easier to define. In English 'landlord' is an example of a compound noun, In Sumerian a few examples are an-pa 'zenith' or gi-dub-ba 'stylus' (lit. reed of tablet.) Presumably this would present a problem to the transliterator, or at least a potential problem, in that (again) word boundaries were not clearly specified in the cuneiform. In concluding on Hyphenation principals, Blacks specifies four main uses: - Hyphenation is used to join all written syllables of a single word together, and: - to join clitics or affixes to the preceding base (or, with verbal proclitics, the following base) - " to join all the elements of proper names" (e.g. amaš-kug-ga Holy Sheepfold) - "to join compound nouns" (here Black elaborates and defines the four types of compound nouns) Sources: 1. Transliteration principles Downloadable at www-etcsl.orient.ox.ac.uk/edition2/technical.php2. Hyphenation principles - Downloadable at www-etcsl.orient.ox.ac.uk/edition2/technical.php3- referenced here are sections from www-etcsl.orient.ox.ac.uk/edition2/language.php4- gate.ac.uk/sale/lrec2006/etcsl/etcsl-paper.pdf5- Example from: www.pitt.edu/~pwl2/pdfs/clitics-handout.pdf An instance of Blacks statement "A whole sequence of clitics can be attached to e.g. the last word of a clause." is discussed on this document. |
|
|
|
Post by amarsin on Aug 21, 2007 9:34:05 GMT -5
One thing not addressed-- but which gets complex-- is the whole 'long form' versus 'short form' debate. For instance, the KA-sign has the value dug4 but also du11, both of which mean 'to speak'. For awhile, it was assumed that in Sumerian, final consonants were often clipped. So, for instance, in verbal chains where there is reduplication (the root is doubled for grammatical reasons), you'll find:
he2-na-a-ga2-ga2
In this case, the ga2-ga2 is a reduplicated form of gar, meaning "to set." But reduplication results in a clipped final consonant, and so */gar-gar/ > ga2-ga2.
Lexical lists attest to signs having phonetic values that are C1V1C and also C1V1.
So the problem is when to read KA as dug4 and when to read it as du11. In some cases, such as verbal reduplication, its pretty well established. But in other cases, it's not.
The current trend is to go with long values whenever possible. So instead of e2-gu4-gaz (house-cattle-slaughter, or "cattle slaughter-house"), many (including ETSCL) will read e2-gud-gaz, where gu4=gud, "cattle".
I'm not a fan of this, though not for any compelling grammatical reasons. As long as you are consistent in what you're doing, it really doesn't matter, I'd say. But you should be aware for when you run across things like gu4...
|
|
|
|
Post by us4-he2-gal2 on Sept 21, 2007 22:17:40 GMT -5
Field Terminology In his article "Right writing" ( ASJ 22) J.S. Cooper suggests some refined philological terminology which would confusion (mainly amongst Sumerologists.) Im not sure to what extent these suggestions have been standardized, but have noted them below. - the article is downloadable here (Thank you Nadia for pointing me to it.) orthography - a set of normative rules for using graphs to render written language. phonogram - a Sumerian graph encoding on the phonetic level (opposed to logogram). phonetic/phonographic/unorthographic/non-standard writing or spelling - the use of phonograms where Sumerian orthography prescribes logograms, or the use of phonograms different from those prescribed by the orthography for a given environment. logophonetic - writing whose graphs encode at both the lexical and phonetic levels (replaces Gelb's logosyllabic). archaic orthography - orthography reflecting the earlier stage of the language from which a given composition derives. orthographic relic - earlier orthography maintained for a specific word of phrase in later stages of language. innovative writing or spelling - a form that is rare or incipient in a given period but common in the following period. conservative writing or spelling - a form that maintains continuity with earlier orthography in opposition to innovative writings that represent continuity with later orthography. manuscript - an exemplar of a composition (usually on a clay tablet, for which see n. 28). text - the reconstructed wording of a literary composition ("the text of 'Inana's Descent'"), or the words on a particular manuscript. recension - a manuscript or group of manuscripts whose text shows significant but minor variations from other manuscripts of a given literary composition. version - a manuscript or group of manuscripts whose text shows significant and major variations from other manuscripts of a given literary composition.
|
|
|
|
Post by amarsin on Sept 24, 2007 14:07:29 GMT -5
I don't think any of Cooper's ideas have been "standardized" even though they are, in general, on the mark in terms how how we need to be distinct and consistent in how we refer to things. But Assyriology is slow to adapt and so I think it's just a matter of time.
|
|
|
|
Post by saharda on Sept 28, 2007 17:25:00 GMT -5
So the problem is when to read KA as dug 4 and when to read it as du 11. In some cases, such as verbal reduplication, its pretty well established. But in other cases, it's not. The current trend is to go with long values whenever possible. So instead of e 2-gu 4-gaz (house-cattle-slaughter, or "cattle slaughter-house"), many (including ETSCL) will read e 2-gud-gaz, where gu 4=gud, "cattle". I'm not a fan of this, though not for any compelling grammatical reasons. As long as you are consistent in what you're doing, it really doesn't matter, I'd say. But you should be aware for when you run across things like gu 4... That was extremely helpful. That explains why some of the time I am completely unable to figure out what sign is being used in a section of Sumerian text (transliterated but not translated) that I should be able to puzzle out at least a few words of. Prelude to Udug Hul being one prime example of a text I can't understand one word of in five from the Sumerian. |
|
|
|
Post by madness on Nov 27, 2007 8:42:21 GMT -5
I have often wondered if there was tonal difference in the pronunciation that distinguish homophones. In D. O. Edzard's article "The Sumerian Language" in Civilizations of the Ancient Near East, vol. 4, p. 2108, a sidebar answers my question.
Sumerian Writing
Different Sumerian words (mostly monosyllabic, but occasionally bisyllabic) were treated as homophones (words pronounced alike but differing in meaning) by the Akkadian scribes, who provided them with identical glosses in syllabic script in the vocabularies they created, e.g., DUG, "pot," DUG, "good," and DUG, "to say." These words, in many cases, were not truly homophones but were distinguished from each other by different vowel length or different shades of vowel quality (u, ū; o, ō; or the like) in spoken Sumerian. The Akkadian scribes, however, either were indifferent to such phonetic subtleties or were unable to denote differences of pronunciation in their syllabic glosses.
Modern Assyriologists have developed a system of identifying such alleged homophones by the addition of accents or numerical indices, such as in DUG, "pot"; DÙG, "good"; DUG4, "to say," (An acute accent [´] replaces the index 2; the grave accent [`] replaces the index 3. The indices were assigned on the basis of supposed relative frequency of the homophones in the texts.) It is to be stressed that this is a modern device completely irrelevant to the actual pronunciation of Sumerian. The term "transliteration" is used for the sign-by-sign transposing of cuneiform into Latin script (including the use of accents and numerical indices). The term "transcription" or "normalization" is used for spelling a Sumerian word in Latin script regardless of its original cuneiform spelling. Thus, the verbal form "he/she said to him/her" is transliterated as MU-NA-AN-DUG4 but transcribed or normalized as MUNANDUG. In this article, hyphens join the transliterations of signs making up a word, while (somewhat unconventionally) periods join the normalizations or morphemes making up a word. Subscript letters represent the determinatives that mark words as referring to a member of a class. including d for "god" (dNINGIRSU), KI for "city" (LAGAŠKI), and GIŠ for "wood(en object)" (GIŠKIRI6).
So, most unfortunately, we may never know how Sumerian is correctly pronounced.
|
|
|
|
Post by madness on Nov 28, 2007 3:35:30 GMT -5
Edzard also states in his article:
The way we transliterate Sumerian into Latin script - and consequently the way we read it - is dictated almost exclusively by the analogy of our reading of Akkadian. Our reconstruction of the phonetic system of Akkadian is itself strongly influenced by our knowledge of the sound systems of the related Semitic languages Hebrew, Aramaic, and Arabic. Consequently - and this should always be kept in mind - at least two steps have distanced our reading and pronunciation of Sumerian from their actual form and acoustic identity, so that in all likelihood we would be totally unintelligible to native speakers of Sumerian who happened to hear our version of their language.
|
|
|
|
Post by ummia-inim-gina on Dec 9, 2007 21:45:27 GMT -5
One thing not addressed-- but which gets complex-- is the whole 'long form' versus 'short form' debate. For instance, the KA-sign has the value du 4 but also du 11, both of which mean 'to speak'. For awhile, it was assumed that in Sumerian, final consonants were often clipped. So, for instance, in verbal chains where there is reduplication (the root is doubled for grammatical reasons), you'll find: he 2-na-a-ga 2-ga 2In this case, the ga 2-ga 2 is a reduplicated form of gar, meaning "to set." But reduplication results in a clipped final consonant, and so */gar-gar/ > ga 2-ga 2. Lexical lists attest to signs having phonetic values that are C 1V 1C and also C 1V 1. So the problem is when to read KA as dug 4 and when to read it as du 11. In some cases, such as verbal reduplication, its pretty well established. But in other cases, it's not. The current trend is to go with long values whenever possible. So instead of e 2-gu 4-gaz (house-cattle-slaughter, or "cattle slaughter-house"), many (including ETSCL) will read e 2-gud-gaz, where gu 4=gud, "cattle". I'm not a fan of this, though not for any compelling grammatical reasons. As long as you are consistent in what you're doing, it really doesn't matter, I'd say. But you should be aware for when you run across things like gu 4... So is this why sometimes the ancient name for Sumer is listed as KI.EN.GI. and other times its KI.EN.GIR. ? I've always wondered about this. From what I can tell KI is "Earth" or "Land" and EN is "Lord" but I haven't been able to figure out the last part yet. |
|
|
|
Post by us4-he2-gal2 on Dec 14, 2007 16:21:02 GMT -5
The Determinative (Classifier) - (With Appreciation to the ePSD for Cuneiform examples) - Most of us are familiar with the divine determinative, that is when the name of a deity is distinguished by the presence of a cuneiform sign. By itself, this sign is read AN (the deity). However, in conjunction with a divine name, the same sign is read 'dingir' the function of which is to signal that the word to follow is the name of a deity - in transcriptions the sign in this function is rendered in superscript i.e. dEnki [ 1] That determinatives were used to identify and classify a wider range of objects may not be as apparent to the non-specialist. Laurence Lo, [ 2] a non-specialist, seems to have done some good homework and outlines the development of cuneiform. He explains "as the system grew more complex, it became hard to tell if a sign was being used as a logogram or a syllabogram (or even which one of the potential sound values the syllabogram can have). To help with the ambiguity, several logograms were overloaded to become "determinatives". They would precede or follow a group of signs that make up a word, and gives a hint to meaning of the word by marking the broad category of objects or ideas the word belongs to." Dietz Otto Edzard's Sumerian Grammar [ 3] provides the following list of determinatives on page 9 - Ive summed the explanations: - AN (or DIĜIR) Precedes divine names - KI (ki "place, earth") following place names e.g. Unug ki- ID2 (íd "river, canal") preceding names of rivers eg. idIgina 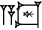 - ĜEŠ - ĜEŠ (ĝeš "wood, tree") preceding terms for wooden object or tree e.g. ĝeš banšur 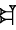 - URUDU - URUDU (erida, eridu, urudu "copper"), preceding terms for metals or metal object 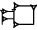 e.g. uruduza-rí-in - DUG (dug "vessel"), preceeding terms of earthenware e.g. duga-da  - KU6 - KU6 (ku 6 "fish"). following the names of fish e.g. suhur-máš ku6- MUŠEN (mušen, "bird") following the names of birds, e.g. tu mušen- LU2 (lú "person"), preceding names of some (male) professions, e.g., lúnu-kiri 6  - SAR - SAR (sar "vegetable"), following the names of garden plants, e.g. šúm sar 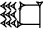 - U2 - U2 (ú "grass", "plant"), preceding names of plants, e.g, úbúr-da 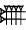 - GI - GI (gi "reed"), preceding reeds and objects made of reed, e.g., gipisan 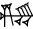 - NA4 - NA4 (na 4 "stone"), preceding the names of stones and stone objects, e.g., na4nunuz - TUG2 (túg "textile, garment"), preceding names of cloth or garments, e.g., ![]() psd.museum.upenn.edu/epsd/psl/img/thumb/Oftd.png[/img]túg psd.museum.upenn.edu/epsd/psl/img/thumb/Oftd.png[/img]túgNIG2.LAM2 - KUŠ "kuš "skin, hide, leather"), preceding leather objects, e.g. kušlu-ub psd.museum.upenn.edu/epsd/psl/img/thumb/Odlm.pngGood examples of the different determinatives in use can be seen at the Digital Corpus of Cuneiform Lexical Texts, where sign lists displayed on that site enumerate a multitude of objects, often more or less obviously grouped by a long segment of a certain determinative. The Corpus can be found here Notes: 1: xoomer.alice.it/bxpoma/akkadeng/cuneiform.htm#determinative2: www.ancientscripts.com/sumerian.html3. The book is called "Sumerian Grammar" (2003) is available in paperback, isbn 1589832523
|
|
|
|
Post by ummia-inim-gina on Dec 14, 2007 17:13:50 GMT -5
Another one I see is the "iti" before the names of months.
|
|
|
|
Post by amarsin on Dec 15, 2007 14:26:06 GMT -5
Another one I see is the "iti" before the names of months. The Sumerian iti is less a determinative and more just the word "month." Though, I guess you can say that about any of the above! In general, though, no one considers iti (or, for that matter, mu (= "year") as such in the same way they consider the ones listed above. |
|
|
|
Post by amarsin on Dec 16, 2007 11:32:12 GMT -5
So is this why sometimes the ancient name for Sumer is listed as KI.EN.GI. and other times its KI.EN.GIR. ? I've always wondered about this. From what I can tell KI is "Earth" or "Land" and EN is "Lord" but I haven't been able to figure out the last part yet. Right. But it's slightly more complex than that. Unfortunately, for the life of me I can't find the actual literature on the topic, so I'm stuck doing this from memory. So it may actually be incorrect and just something I made up one day. So the final sign in the word is GI, which looks like this: This sign can have several different meanings, most typically 'reed'. But this doesn't help us, since PLACE-LORD-REED doesn't mean much. Before we consider that much further, though, let's look at the phonetic value of the sign, since that was what led to your question to begin with. Lexically, the GI-sign has the phonetic value /gi/ or /ge/. There is no equivalent /gir/. This is not like the KA-sign I talked about above, which, in lexical lists, can have the value /du/ or /dug/. So how do we know that this GI is /gir/? Well, one clue is in the Ur III personal name Ur-Shulgira, written ur- dšul-gi-ra. The pattern lu 2/arad 2/ur-X, meaning "'man'/'slave'/servant (?)' of X" where X is usually a divine name, is extremely common. So we'd expect ur- dšul-gi-ra to be the same thing. But if so, what's the final -ra? In Sumerian, the genetive marker-- the "of" in expressions like "something of something else"-- is marked by a final -ak. However, that /k/ is almost always dropped, so instead we just find a final /a/. Often, when the word to which the -a(k) is to be attached already ends in a vowel, the -a(k) is dropped altogether, assuming some sort of desire for vowel harmony. Thus, the common Girsu name ur- dba-u 2 is probably really /ur- dba-u 2-ak/, with the /k/ dropped and the /a/>/u/. Got it so far? If so, then you'll see that we're stuck with an unusual /r/ in the name ur- dšul-gi-ra. What this suggests is that the final part of the name Šulgi was really /gir/ and not just /gi/. This is fine, since the name Šulgi doesn't make much sense. The šul means 'youth' or some such, so adding a 'reed' is dumb. So if things like ki-en-gi and šul-gi have a final /r/, what do we make of that? Here is where things get questionable (for me) because I am doing this from memory and I may have remembered it wrong. But for some reason, it's reasonable to assume that the /gir/ is from gir 15, meaning "noble" or the like. Oh! I just figured it out. Or at least, I have more compelling evidence. Ok, so the native name for "Sumerian" was eme-gir 15, meaning something like "noble tongue" or whatever. But we see some instances where the GI-sign is substituted for gir 15. In a Šulgi hymn (called "Šulgi C"), we see a line: eme mar-tu nig2 eme-gi-ra-gin7 he2-en-ga-zu-am3Meaning something like, "I know Amorite as well as I do Sumerian." Now, it may be that in early inscriptions (and I'm just not familiar enough with those), ki-en-gi was actually written ki-en-gir 15, and then in later periods, the GI-sign is substituted (note that the sign for gir 15 also has the phonetic value gi 7). But either way, that seems to be the solution. HOWEVER: my guess is that the meaning of "place (of?) the noble lord(s)" or something for ki-en-gi(r) is probably a false etymology. Just like "London" or "Berlin" I imagine that the original meaning "Kengi(r)" has been lost to time. |
|
|
|
Post by us4-he2-gal2 on Jun 19, 2008 13:00:31 GMT -5
German Influence on Assyriological Convention
- About phonetic accents; for Homophonic accents, refer again to the top of this thread. -
I have taken a brief note below from G. Leick 1994, in the introductions section the author addresses some words to Non-Assyriological Readers. In this I see more plainly, for the first time, the German influence on Assyriological convention and it's almost ridiculous that I hadn't consciously realized this before as I have been reading Assyriology for years, read into the importance of German Scholarship numerous times, and in addition am studying German language. In any case - the note from Leick:
Due to the fact that German scholars composed the first lexical works on Akkadian and Sumerian, their principals of transliteration were influenced by German phonetics. The question of the actual pronunciation of both languages is of course, unanswerable, especially in the case of Sumerian, which is not related to any other linguistic group. Assyriologists meanwhile read transliterations, by convention, as if they were written in German.
Hence the vowel 'a' is as in English 'far"; 'e' as in English 'hence', 'i' as in 'is', and 'u' as in 'full'.
The letter 'š' stands for 'sh', 'h' is pronounced as in Scottish 'loch".
|
|
|
|
Post by amarsin on Jun 30, 2008 21:18:33 GMT -5
Assyriologists meanwhile read transliterations, by convention, as if they were written in German. Hence the vowel 'a' is as in English 'far"; 'e' as in English 'hence', 'i' as in 'is', and 'u' as in 'full'. The letter 'š' stands for 'sh', 'h' is pronounced as in Scottish 'loch". [/color]
[/quote]That's not 100% correct-- or at least not in my experience. I'd say the following: ba = "ba" (rhymes with "ha") be = "bay" bi = "bee" bu = "boo" So mostly, it's right. I just don't think the /i/ is right. It's not like the /i/ in "is" it's a long e, like beet or feet. When you encounter the marker of plurality hi-a, you say "hee-ah". At least, that's how we did it in class. |
|
|
|
Post by us4-he2-gal2 on Jul 4, 2008 12:29:39 GMT -5
The devil is in the details as they say *g* . So yes on the German influence on Assyriological convention, maybe no on some of those particulars.. I would say your point is a good one Amarsin, as when I do my German ABC's on the way to work I always say (phonetically) "e-f-geh-hah-ee-yot-kah" (instead of e-f-geh-hah-i-yot-kah) but then, I'm learning the from an tourists guide and cant be held accountable  |
|
|
|
Post by ummia-inim-gina on Aug 2, 2009 14:15:50 GMT -5
So I just finished re-reading through Dietz Otto Edzard's "Sumerian Grammar." I knew going back into it, that with me having no previous linguistic studies there would be a lot of terminology I wouldn't understand at first. This perspective turned out to be a bit of an understatement considering that I recognized more of the transliterated Sumerian words in the book than I did the "English" linguistic nomenclature. (I'll note that the spell checker for the board didn't recognize most these terms either!)
Now I'm backing up and studying the linguistic nomenclature from the book and then I intend to reanalyze the book with a greater understanding. I figured I would detail out my grammatical journey here in case anyone else ends up walking in these same footsteps. Going into this I could identify elementary grammatical terms that one would find in a public school English class (nouns, verbs, adjectives, pronouns, adverbs, etc.) but the first term in the book that I had never encountered before was the term "Ergativity" looking it up in the wikipedia lead me to a greater effort which is the topic of this post:
Grammatical Case:
Dietz pg.33
5.4 Case
Sumerian has ten cases: (1) absolutive, (2) ergative, (3) genitive, (4) locative, (5) dative, (6) comitative, (7) ablative (-instrumental) (8) terminative, (9) directive, (10) equative.
Here is the Wikipedia's explanation of these terms:
(Dietz's explanations are very similar and I can copy/paste this way.)
Grammatical Case
"In grammar, the case of a noun or pronoun indicates its grammatical function in a greater phrase or clause; such as the role of subject, of direct object, or of possessor. While most languages distinguish cases in some fashion, it is only customary to say that a language has cases when these are codified in the morphology of its nouns — that is, when nouns change their form to reflect their case. (Such a change in form is a kind of declension, hence a kind of inflection.) Cases are related to, but distinct from, thematic roles such as agent and patient; while certain cases in each language tend to correspond to certain thematic roles, cases are a syntactic notion whereas thematic roles are a semantic one.
Absolutive case
In ergative-absolutive languages, the absolutive (abbreviated ABS) is the grammatical case used to mark both the subject of an intransitive verb and the object of a transitive verb. It contrasts with the ergative case, which marks the subject of transitive verbs.
Ergative case
The ergative case is the grammatical case that identifies the subject of a transitive verb in ergative-absolutive languages.
In such languages, the ergative case is typically marked (most salient), while the absolutive case is unmarked. New work in case theory has vigorously supported the idea that the ergative case identifies the agent (the intentful performer of an action) of a verb (Woolford 2004).
Genitive case
In grammar, the genitive case (also called the possessive case or second case) is the case that marks a noun as modifying another noun. It often marks a noun as being the possessor of another noun but it can also indicate various relationships other than possession; certain verbs may take arguments in the genitive case; and it may have adverbial uses (see Adverbial genitive). Modern English does not typically mark nouns for a genitive case morphologically — rather, it uses the apostrophe ’s or a preposition (usually of) — but the personal pronouns do have distinct possessive forms.
Locative case
Locative (also called the seventh case) is a grammatical case which indicates a location. It corresponds vaguely to the English prepositions "in", "on", "at", and "by". The locative case belongs to the general local cases together with the lative and separative case.
Dative case
The dative case is a grammatical case generally used to indicate the noun to whom something is given. For example, in "John gave a book to Mary".
Comitative case
The comitative case, also known as the associative case, is a grammatical case that denotes companionship, and is used where English would use "in company with" or "together with".
Ablative case
For the spacecraft technology, see Ablative armor.
In linguistics, ablative case (abbreviated ABL) is a name given to cases in various languages whose common characteristic is that they mark motion away from something, though the details in each language may differ. The name "ablative" is derived from the Latin ablatus, the (irregular) perfect passive participle of auferre "to carry away".
Instrumental case
The instrumental case (also called the eighth case) is a grammatical case used to indicate that a noun is the instrument or means by or with which the subject achieves or accomplishes an action. The noun may be either a physical object or an abstract concept.
Terminative case
In morphology, the terminative case is a case to tell where something ends (i. e. answers "Until what point in space or time?").
Directive case
No entry for directive case yet.
Equative case
Equative is a case with the meaning of comparison, or likening. The equative case has been used in very few languages in history.
|
|
|
|
Post by us4-he2-gal2 on Aug 7, 2009 0:48:08 GMT -5
Hey Ummia! Wonderful that you have made some Sumerian grammar notes for us! ;] I can certainly understand your situation with the Edzard book and the linguistic jargon - I have found it quite obtuse in the past, but it's coming to the point where I'd better learn to like it and fast. As for Sumerian, I look forward to day when my linguistic learning has progessed to the state that Edzard's grammar seems feasible or plausible. Certainly the 10 cases of Sumerian which you start with here are a major learning curve with the language I believe! Nice work  |
|
|
|
Post by creed on Aug 17, 2009 10:07:25 GMT -5
In regarding the 'The Determitive' post by us4 - and recently reading through stuff on the 'me' or 'mes' - from what I gather is a sort of codex for civilization that Enlil gave to Enki who would decide upon the when and where of it's dissemination (an interesting point in itself in regards to Luciferian 'archeotheology') - would it not follow that 'The Determitive' used in words would stem from these 'mes' or at least the inscribed symbol or symbols.
Following these parameter of logic a given set of text may have a theme - the theme being a single 'me' or several of them. And going further - if this theme carried over into the rest of the text it would be possible to quickly identify and place a symbols 'form' - or present family - because it falls under the influence of a particular 'me' or 'mes'. Like music when you play a song in a certain key.
Also, if I am reading some other text correctly, early sumerian writing was mnenonic and agglutinated - it's purpose not to be read verbatim but to indicate to an individual information in a form easily readable and just as easily responded to in like form. It would be like us reading a grocery list or a bill of lading from a ship - we would and I presume they would not talk to each other this way. From here I think this is where the confusion comes - because maybe this sort of 'outline instead of content' logic carried over and was an element in the evolution of there inscriptions.
Well enough for now.
|
|
|
|
Post by enkur on Oct 22, 2010 6:28:04 GMT -5
Would be extremely helpful to see some examples of Sumerian compound verbs as well as other grammatical particularities in the original cuneiform texts. I will do my research anyway, but if somebody could save me the time I would be extremely grateful...
|
|
|
|
Post by us4-he2-gal2 on Dec 31, 2013 22:18:33 GMT -5
Update on Homophony and Polyphony Hey e n e n u r u: Just to update, I have been reading a general guide to transliteration written by I.J. Gelb in 1948. Reflecting directly on the posts which started this thread and which discuss homophony and polyphony, Gelb mentions some important points based on his personal study of cuneiform throughout the periods - he cautions the student of cuneiform that despite the alarm sometimes expressed about how complicated homophony and polyphony can be, his own studies have demonstrated that within a certain period and a certain area, signs do not overlap as much as the hype leads one to think - here is a snippet from that discussion:
|
|
|
|
Post by madness on Mar 4, 2015 9:25:17 GMT -5
A remark on typographical correctness: Cuneiform translations are often afflicted with [breaks] in text. Much of the time, these [breaks] can be [restored]. On this forum we have always sought to accurately re-present translations with their correct typography. I have, however, identified a problem. Recently proboards updated all hosted boards to a new format. This update brought bbcode changes. These changes include the interpretation of certain l[e]tters within brackets as code. In our description of Marduk, to provide an example, we say that "Nabû is your bility."But wait a minute... something went wrong here. I wanted to say "Nabû is your [a]bility." The [a] was interpreted as an <a> tag, causing a change in font colour to, and pseudo-hyperlinkage of, the subsequent text. The solution to this problem involves using another piece of bbcode which cancels such interpretation. That code is noparse: [noparse][a][/noparse] This is a pain, yes, but it is preferable to erroneous bbcode change. There may be, I fear, many such errors throughout all transliteration/translation-heavy posts prior to the update. Indeed, the very first post in this thread contains an example of such error, where the wish to indicate "by the signs [a] 'tu one', [another one]" is rather an indication of something quite different. The problem is also found a number of times across posts in this thread... |
|
|
|
Post by sheshki on Mar 5, 2015 19:39:53 GMT -5
Thank you for pointing that out. I will have a look through my posts...there may be some candidates...
|
|
|
|
Post by madness on Mar 6, 2015 7:10:25 GMT -5
[i] is the other one to watch out for, since it is interpreted as italics. The situation is worse than I initially imagined. It is not merely the case that [a] or [i] are interpreted as code - if these letters are placed at the beginning of any bracketed content then interpretation still occurs. For instance [a bcdef]ghijk becomes ghijkAnd [i utu] Why have you forsaken me? is rendered Why have you forsaken me?Worse still, proboards conveniently deletes what it sees as excess in the code. Meaning that what was originally written as [a bcdef] is cut down to [a] - the rest is lost to the abyss. |
|



 Surely he's joking.. I should mention there is some cdli activity on sign lists:
Surely he's joking.. I should mention there is some cdli activity on sign lists:







